OAHOT-blog 4/2021: Learning analytics from general insights to personal control
Writer:
Mohammed Saqr, senior researcher, project researcher in the OAHOT-project
We are living in a digitized world, where almost every service is digitized in Finland. The digitalization of services resulted in large amounts of data about users. Consequently, data took the center stage in our life and has become the driver for improving many services. For instance, data is used to help improve banking services and to better recommend products (Romero & Ventura, 2020). Investing in the possibilities of data is at its highest in history and is expected to continue to rise as more and more digital services are consumed (Saqr, 2017). Learning is no exception; learners generate massive amounts of data that can be used to improve learning, teaching and the learning platforms (Saqr, 2015).
Learning analytics has emerged to harness the potential of data in learning environments (Saqr, 2015). In simple words, learning analytics tries to translate students’ clicks into recommendations and advice (Romero & Ventura, 2020). In doing so, the results of research can help a teacher to understand how his/her class is doing, who needs support and what kind of support they need (Saqr et al., 2019). As we understand learning better, we have the opportunity to improve it and offer our students a better service (López-Pernas et al., 2021). Learning analytics can also help decision makers so that decisions about students are better informed by the data.
So far, there have been many examples where learning analytics have helped students, teachers and administrators to improve learning, or improve decision making. But, it is not as easy as it seems, learning is complex and dynamic, by complex I mean it involves all of our senses, is influenced by environment and peers, and develops over time (dynamic). Therefore, we still have many unexplored potential and opportunities (Romero & Ventura, 2020).
Learning analytics is not without challenges. However, the most pressing challenge is how to balance privacy with usability. This is not a trivial issue, since we should never compromise students’ privacy and right to control over their data, and in the same time, be able to help them with their learning. There is intensive work going to solve this dilemma, such as proposing guarantees, policies and strict protocols. The bottom-line of such efforts is that students’ privacy and autonomy are preserved and well-respected (Tsai & Gasevic, 2017).
A new innovative approach gives the student total control over their data to be collected, saved and analyzed on the student device (López-Pernas & Saqr, 2021; Saqr & López-Pernas, 2021). In that approach, students have control over which data is collected from which devices and apps. This control implies that students can add data sources and choose which data are collected and for how long. Algorithms are trained locally (e.g., on the phone) using student’s own data. The concept of training means in simple words that algorithms need some data to learn. The algorithms try to learn some patterns in the data and generate rules or predictions. For instance, for an algorithm to learn to identify giraffe photos we feed it with many photos of giraffes. The algorithm will learn that an animal with a long neck is probably a giraffe. In the same way, if we feed the algorithm data from the same student, it will be able to learn more relevant information about that student. This is in contrast to current implementations that collect data from many different people and algorithms generate insights based on it.
The implementation on the student’s own phone will make insights generated and displayed in a personalized learning analytics dashboard based on students’ own data. If the students want, they can enable sharing data and/or insights. Which implies that the student can opt-in sharing and choose which data to share, for how long, and with whom. An advantage of this approach is that the student retains the data between institutions, figure (1).
Algorithms are not foolproof, and humans are far from predictable or consistent and therefore, learning from past data may not tell us how the future unfolds. Nonetheless, it may offer reasonable guidance and help.
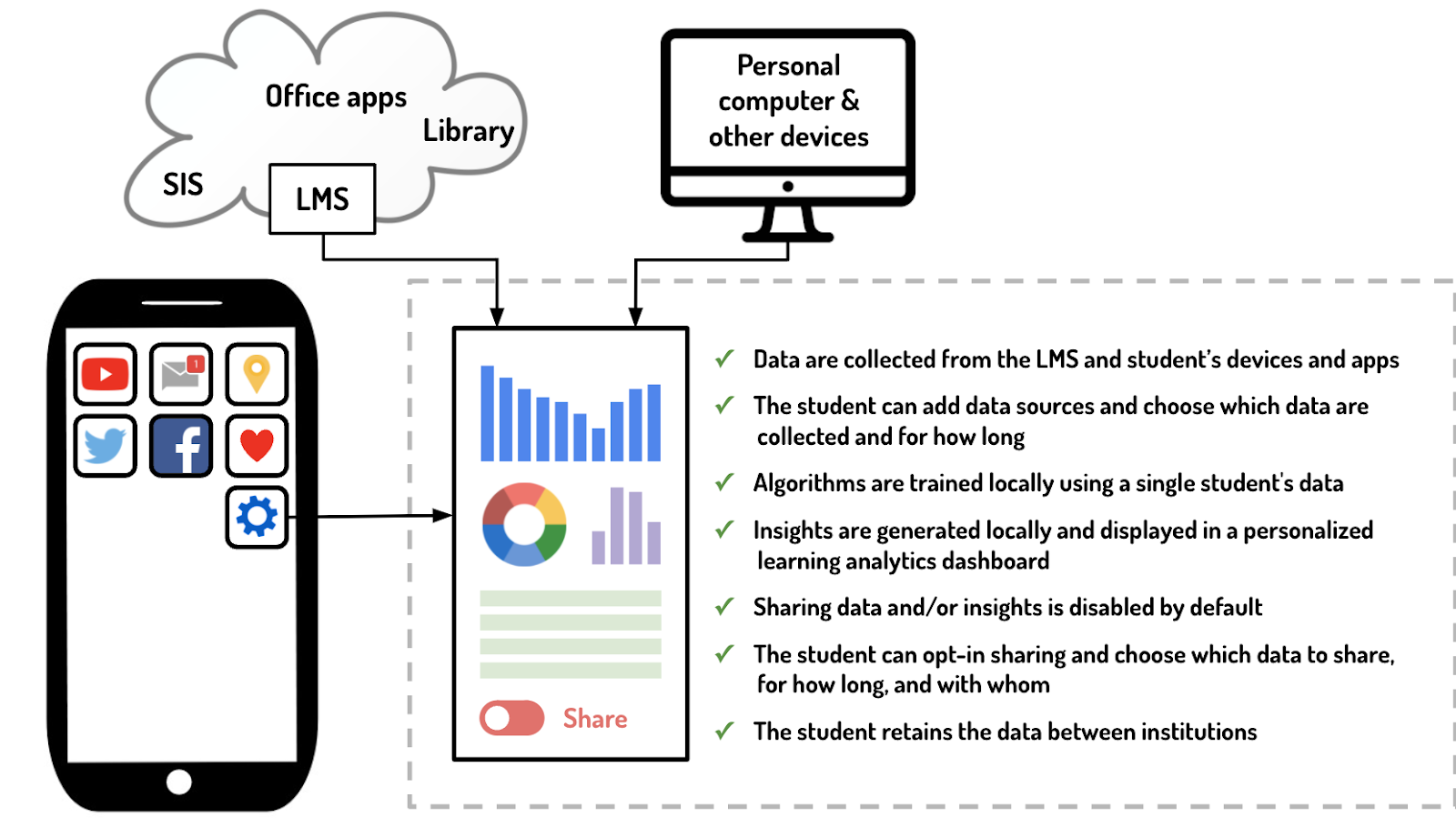
Figure 1 proposed personal learning analytics model (López-Pernas & Saqr, 2021)
References
Saqr, M., & López-Pernas, S. (2021). Idiographic learning analytics: A single student (N=1) approach using psychological networks. Companion Proceedings 11th International Conference on Learning Analytics & Knowledge (LAK21), 397–404.