Käsinkirjoitetun tekstin koneellinen tunnistaminen Kansallisarkistossa: Opetusaineistoa supermallille
Sanna Joska ja Ilkka Jokipii
Kansallisarkisto on mukana Kaupungit Ruotsin suurvallan itärajalla -projektissa kehittämässä 1600-luvun käsialamallia yhdessä projektissa työskentelevien tutkijoiden kanssa. Yhteistyön tuloksena kehitetään Kansallisarkiston koneellista tekstintunnistusta hyödyntäviä käsialamalleja lukemaan paremmin 1600-luvulla kirjoitettua käsialaa. Kansallisarkisto vastaa hankkeessa lähdeaineistojen, 1600-luvun tuomiokirjojen, koneellisesta tekstintunnistuksesta. Tekstintunnistuksen avulla saadaan tuhannet käsin kirjoitetut tuomiokirjasivut sähköiseen muotoon, jolloin niiden käyttö tutkimuksen lähdeaineistona helpottuu olennaisesti.
Kansallisarkistossa on hyödynnetty HTR-teknologiaa (handwritten text recognition) jo muutaman vuoden ajan. Olemme mm. prosessoineet yli 3 miljoonaa kuvaa 1800-luvun tuomiokirjoja yhteistyössä READ-COOP-osuuskunnan kanssa. Viimeisen vuoden aikana Kansallisarkistossa on keskitytty omien käsialamallien kehittämiseen. Tavoitteena on luoda käsialamallit, jotka osaavat lukea käsinkirjoitettua aineistoa aina 1500-luvulta 1900-luvulle ja sitä kautta parantaa arkistoaineistojen saatavuutta ja käytettävyyttä. Käsialamallien kehittäminen vaatii paitsi koneoppimisosaamista, myös vanhoja käsialoja lukemaan kykenevien historiantutkijoiden taitoja. Kansallisarkiston näkökulmasta projektin parissa tehtävä yhteistyö onkin malliesimerkki siitä, miten voidaan yhdistää tutkijoiden asiantuntemus Kansallisarkiston koneoppimis- ja aineisto-osaamiseen ja saada paitsi molempia tahoja, myös tutkimuskenttää yleisemmin hyödyntäviä tuloksia.
Kaikki alkaa digitaalisista kuvista
Kansallisarkiston näkökulmasta käsialamallin kehittämistä varten aineistosta on oltava laadukkaat digitaaliset kuvat. Projektin lähdeaineistona olevia 1600-luvun raastuvan- ja kämnerinoikeuksien renovoituja tuomiokirjoja säilytetään keskusarkistossa Mikkelissä. Aineistot on aikoinaan kuvattu mikrofilmille, jonka kuvat oli sittemmin digitoitu. Mikrofilmikuvien digitointi tuottaa mustavalkoisia kuvia, jotka vaihtelevat laadultaan tutkijalle kohtuullisen lukukelpoisista lukukelvottomiin. Koneellista tekstintunnistusta ajatellen mikrofilmiltä digitoidut kuvat ovat usein aivan liian tummia, eikä teksti erotu taustasta tarpeeksi varsinkaan niissä tapauksissa, joissa sivun kääntöpuolelta kuultaa mustetta läpi tai alkuperäinen sivu on muuten historian saatossa värjäytynyt. Ensimmäinen askel oli siis varmistaa, että lähteenä käytettävistä tuomiokirjoista on saatavilla uudet, nykyaikaisilla laitteilla kuvatut digikuvat. Tuomiokirjat digitoitiin uudelleen keskusarkistossa. Uudet kuvat ovat hankkeen tutkijoiden käytössä ja vapaasti nähtävissä Kansallisarkiston Astia-verkkopalvelussa.

Opetusaineiston tuottaminen
Toinen askel käsialamallin kehittämisessä on opetusaineistojen tuottaminen. Käsialamalleja kehitetään opettamalla konetta lukemaan erilaisia käsialoja ja tätä varten tarvitaan puhtaaksikirjoitettua opetusaineistoa. Mitä enemmän puhtaaksikirjoitettuja sanoja, sitä parempi malli ja tekstintunnistustulos. Käsialamallin ohella aineistolle on kehitettävä myös segmentointi- eli tekstialuemalli, jonka avulla kone tunnistaa, missä kohdassa kuvaa tekstiä esiintyy. Sekä tekstialueiden korjaaminen että tekstin puhtaaksikirjoittaminen ovat varsin työläitä työvaiheita, jotka vaativat paitsi aikaa ja huolellisuutta, myös historiallisten aineistojen lukutaitoa.
Tekstintunnistukseen liittyvien opetusaineistojen tekemiseen Kansallisarkistossa käytetään pääasiassa Transkribus-työkalua. Kyseessä on READ-COOP-osuuskunnan, jonka jäsen Kansallisarkisto on, kehittämä tekstintunnistusohjelma, joka on vapaasti käytettävissä netissä.
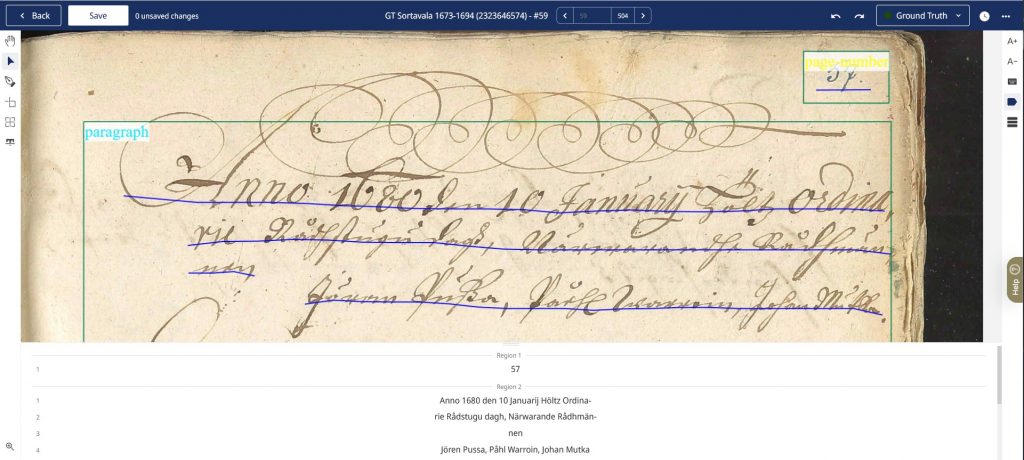
Opetusaineiston tekeminen alkaa lataamalla digitoidut kuvat Transkribukseen, jossa niille ajetaan tekstialueiden ja rivien tunnistus. Transkribuksen layout-tunnistus on varsin hyvä, mutta ohjelma tekee edelleen virheitä, jotka tulee korjata käsin, ennen kuin tekstiä voi alkaa puhtaaksikirjoittaa.

Transkribus merkitsee tunnistamansa rivit vaaleansinisinä laatikkoina (line polygons) ja tummansinisinä viivoina (baseline). Esimerkkikuvassa kaikki rivit eivät ole tunnistuneet kokonaisina, vaan osa riveistä on liian lyhyitä ja osa riveistä on katkennut kesken. Vasemmassa yläkulmassa on lisäksi pari virheellistä riviä alta kuultavan tekstin takia. Virheelliset rivit poistetaan, katkenneet rivit yhdistetään ja liian lyhyenä tunnistuneet rivit pidennetään kattamaan koko teksti.
Tekstialueiden korjaamisen jälkeen voidaan kirjoittaa sivuilla olevat tekstit puhtaaksi. Viimeistään tässä vaiheessa työtä paleografinen osaaminen on välttämätöntä. Kansallisarkisto sai puhtaaksikirjoitetut opetusaineistot hankkeelta, joten tehtäväksemme jäi kopioida puhtaaksikirjoitettu teksti riveittäin Transkribukseen. 1600-luvun oikeusjuttujen mielenkiintoiseen sisältöön ei kopioidessa valitettavasti ehdi sen suuremmin paneutumaan, paitsi tarkastaakseen, että rivit ovat oikeassa järjestyksessä.
Kun tekstialueet ja rivit on tarkistettu ja puhtaaksikirjoitetut tekstit kopioitu Transkribukseen, voidaan työ tallentaa tilaan ”GT” eli Ground Truth. Termiä käytetään kuvaamaan valmista opetusaineistoa. Valmista tuli, ja aineistoa voidaan nyt käyttää kouluttamaan käsialamallia!
Käsialamallin kouluttaminen
Transkribuksessa on mahdollista kouluttaa niin tekstialue- kuin käsialamalleja ja prosessoida aineistoja, mutta palveluiden käyttö on maksullista. Etenkin isojen, tuhansia (tai jopa miljoonia!) sivuja sisältävien aineistokokonaisuuksien prosessoinnin hinta nousee korkeaksi, joten Kansallisarkisto on siirtynyt kouluttamaan käsialamallinsa ja prosessoimaan aineistonsa itsenäisesti. Alkuvuodesta 2024 Kansallisarkisto pääsi Tieteen tietotekniikan keskus oy:n eli CSC:n akateemisen käytön piiriin ja aineistojen prosessointi tapahtuu jatkossa heidän palvelimillaan.
Kansallisarkiston omien käsialamallien koulutuksen prosessia varten kuvat ja transkriptiot sisältävät xml-tiedostot ladataan ulos Transkribuksesta. Xml-tiedostojen avulla kuvista irrotetaan rivikuvat ja niihin liitetään transkriptiot. Näiden rivikuvien pohjalta aloitetaan käsialamallin koulutus, joka kestää laskentakapasiteetista ja aineistomäärästä riippuen muutamista tunneista pariin viikkoon.
Omien mallien avulla on mahdollista päästä todella hyviin tuloksiin, ja Kansallisarkiston viimeksi kouluttama supermalli-työnimellä kulkeva käsialamalli saavuttaa jopa 3,7 virheprosentin käsialoista 1600-luvulta aina 1900-luvun alkupuolelle asti. Tutkimushankkeen aikana tehtävien opetusaineistojen avulla parannetaan tätä mallia 1600-luvun aineistojen osalta.