1. Research data and data management
Research material, that is also called research data, refer to the material produced by different methods or used during the study (eg. master’s thesis) on which the research results are based. There are several types of research data and depending on the discipline and the research what type of research data are used.
Research data are for example:
• survey and interview data, images, videos, measurements, researcher’s notes
• software, source codes
• samples
• organized collections.
Nowadays research data are primarily in the digital form but can also refer to analogue or physical material such as paper documents or blood or plant samples. The researchers can collect or produce the data themselves or reuse the existing data produced by someone else.
Existing data include documents, such as historical texts, literature, newspaper articles or open research data produced by other researchers. Open research data can be found from data repositories (= a platform for publishing the research data) or archives. These existing datasets provide opportunities for students to practice analysis because they can utilize larger datasets than they could collect themselves. Existing data can also be combined with the research data produced by you in the master’s thesis.
A Data Repository = a platform for publishing the research data. The Helsinki Term Bank for the Arts and Sciences; Tieteen termipankki 25.08.2023: Nimitys:repositorio.
Open research data refer to open access data. Fully open access data are available and free of charge to the general public, such as Beetle Diversity (Zenedo). There may also be restrictions to access the data, in which case the data are only available for a specific purpose, such as research or theses. The use of data may require registration with a service that provides the data. An example: University Student Health Survey 2004 (Finnish Social Science Data Archive).
When collecting data, it is important to ensure that the data are handled and stored safely. It is important to keep the file and folder structure of the data in order from the beginning of the research project (eg. master’s thesis), so that both the collector of the data and potential users know how and when the data have been collected, what kind of information the data contain and how the data can be found. In order to do this, data documentation and metadata (= descriptive details of the data) are needed. Metadata describes the context, content and structural properties of the data as well as administrative or descriptive information about the data. One example of metadata is naming and labelling variables clearly so that anybody who will reuse the data, will be able to understand the data. Thus, good metadata ensure the integrity of the research data, and promote the findability and reusability of the data.
Documentation and metadata
A careful documentation of research data is important because it ensures the findability and reusability of the data. Good data documentation and description include concise information on variables and measurement units or questions in the questionnaire that has been used in the research project (eg. master’s thesis). Detailed documentation helps you to interpret the data if you, for example, need to come back to the data later on. It is therefore worth considering what information you would need in this case.
Documentation and description of the data (metadata) can be stored as a free-form text file in connection with the dataset or as a separate file. It can be, for example, a README-type text file providing necessary information related to the data, such as the data collector, description, methods used and information related to the files, such as explanations of abbreviations.
Plan what kind of information you need to organize and use the data. Think about what kind of folder structure you need for the files and how you name the files. Create a folder structure, which helps to find information, and a meaningful, consistent way to rename files so that the name already tells you essential information about the file. Remember version control. Note that if you are using ready-made data from a research group there might be instructions from the research group on how keep the data in order.
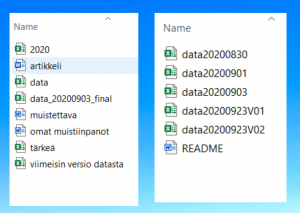
Tips for file naming:
- Create meaningful but brief names.
- Separate words by underscore (_) in the file name.
- Avoid using spaces and special characters in the file name.
- If using a date in the file name, always state the date ‘back to front’: year, month, day (YYMMDD ) and/or hours, minutes, seconds (HHMMSS).
- The version number should be indicated in the file name (“V” for version followed by the version number).
Sources and references:
The Helsinki Term Bank for the Arts and Sciences; Tieteen termipankki.
Purdue University, Data management for Undergraduate Researchers.